大数据 解锁大问题的钥匙与数据处理、存储的支撑服务
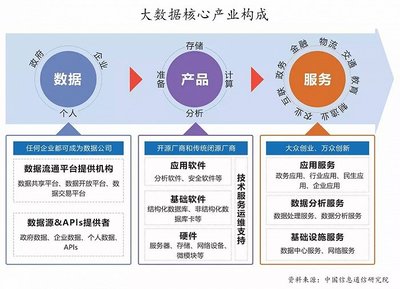
在当今数字化时代,我们面临的问题日益复杂和庞大,从城市交通拥堵、流行病预测到气候变化分析、精准医疗,无不涉及海量、多源、高速生成的数据。传统的数据处理方法在这些“大问题”面前显得力不从心。而大数据技术,正凭借其强大的数据处理和存储支持服务,成为解决这些大问题的关键钥匙。
一、大数据如何解决大问题:从洞察到决策
大数据解决大问题的核心逻辑在于:通过收集和分析远超传统数据库处理能力的庞大数据集,揭示隐藏的模式、未知的相关性和趋势,从而将数据转化为深刻的洞察和可执行的智能。
- 全面感知与精准预测:大数据使我们能够近乎实时地收集和分析来自物联网设备、社交媒体、交易记录等多维度的信息。例如,在公共卫生领域,通过整合搜索关键词、移动定位、医疗报告等数据,可以更早、更精准地预测并追踪疫情爆发点,为防控决策赢得宝贵时间。
- 个性化与优化:在商业领域,大数据分析客户行为、偏好和历史交互,能够实现产品推荐、动态定价和个性化营销,极大提升用户体验和商业效率。在工业领域,通过对生产线上传感器数据的实时分析,可以预测设备故障,优化生产流程,减少停机损失。
- 复杂系统模拟与决策支持:对于如智慧城市、全球供应链、金融风险等复杂系统,大数据可以构建高精度的数字孪生模型。通过模拟不同策略下的系统反应,决策者可以在虚拟环境中“试错”,找到最优解决方案,从而做出更科学、更前瞻的决策。
二、数据处理与存储:大数据的坚实基座
大数据价值的释放,离不开底层强大的数据处理和存储支持服务作为技术基座。这些服务共同构成了大数据解决方案的“引擎”和“仓库”。
1. 数据处理支持服务:从原始数据到可用信息
数据处理是将原始、杂乱的数据转化为结构化、高质量信息的过程,主要包括:
- 数据采集与集成:使用如Apache Flume、Kafka等工具,从各种来源(日志、传感器、数据库)实时或批量地收集数据,并进行清洗、去重、格式化,解决数据孤岛问题。
- 数据存储与管理:这不仅是简单的存放,更是为高效分析做准备。数据湖(Data Lake)允许存储原始格式的海量数据,而数据仓库(Data Warehouse)则存储经过清洗和建模的结构化数据,服务于不同的分析场景。
- 数据计算与分析:这是核心环节。批处理框架(如Hadoop MapReduce, Spark)用于处理历史数据,进行深度挖掘;流处理框架(如Spark Streaming, Flink)则对实时数据流进行即时分析,满足低延迟需求。
- 数据治理与安全:确保数据在整个生命周期中的质量、一致性、合规性和安全性,包括元数据管理、数据血缘追踪、访问控制和隐私保护(如差分隐私、联邦学习)。
2. 数据存储支持服务:弹性、可靠与高性能的保障
海量数据的存储需求催生了革命性的存储解决方案:
- 分布式文件系统:如HDFS(Hadoop Distributed File System),将大文件分割成块,分布式存储在廉价的商用服务器集群上,提供了高吞吐量的数据访问能力和高容错性。
- NoSQL数据库:针对不同数据类型和访问模式,出现了键值存储(如Redis)、文档数据库(如MongoDB)、列族数据库(如HBase)和图数据库(如Neo4j),它们放弃了严格的关系模型,换来了极致的可扩展性和灵活性。
- 云存储服务:以AWS S3、Azure Blob Storage、阿里云OSS为代表的云对象存储,提供了近乎无限的容量、极高的持久性和按需付费的模式,使得企业无需自建数据中心即可安全、经济地存储海量数据。
- 新兴存储技术:如计算存储一体化、持久内存(PMEM)等,正在进一步打破存储与计算之间的瓶颈,提升数据处理效率。
###
大数据并非简单的“数据大”,而是一套以数据为中心,集先进的数据处理、存储、分析技术于一体的系统性解决方案。它通过将强大的数据处理引擎与弹性可扩展的存储架构相结合,赋予了我们洞察复杂现象、预测未来趋势、优化现实世界的能力。面对日益增长的社会经济挑战,持续发展和完善的数据处理与存储支持服务,将是驱动大数据持续挖掘价值、真正解决“大问题”的不竭动力。企业和社会组织只有夯实这一技术基座,才能在未来数据驱动的竞争中赢得先机。
最新产品
短信复活 数据处理和存储支持服务如何复活怀旧通讯体验
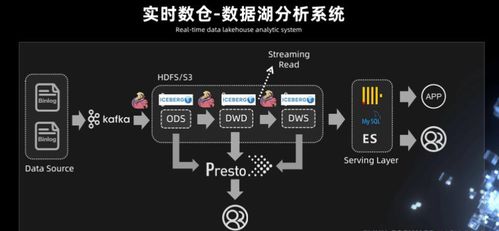
漫谈大数据 实时数据仓库与大厂实际应用的冷与热
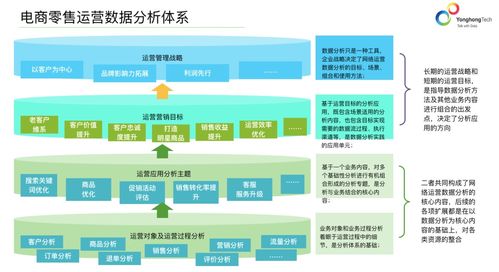
释放数据价值 大数据分析如何助力电商获客又增收
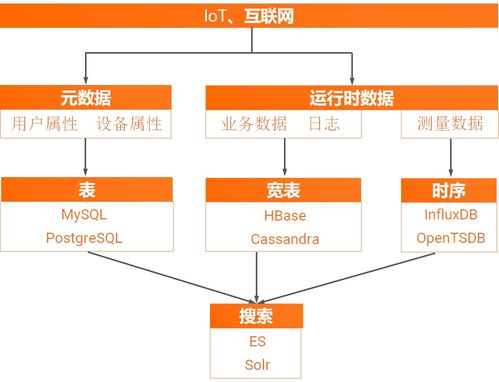
存储成本降低80% 阿里云发布业界首款云原生多模数据库,重塑数据处理与存储新范式

数据中心机房运维全攻略 高效保障数据处理与存储支持服务
Capture One下载安装实测 照片处理不容错过的工具与数据处理存储支持服务详解

阿里全面进军物联网 继电商、云计算后的新主赛道
WPS移动版惊艳亮相 地铁上的Excel办公已成现实

智能化浪潮下的卫浴革命 大白卫浴获小米与顺为资本战略融资
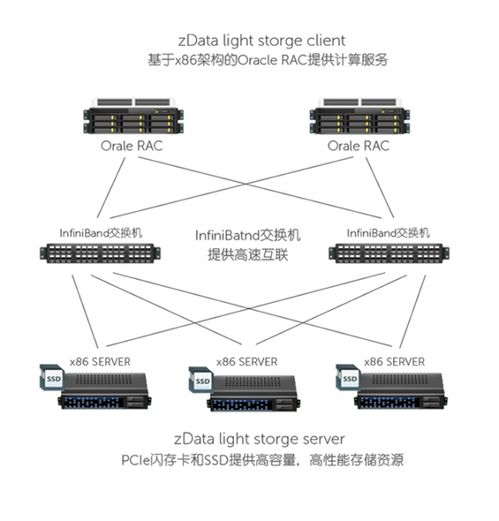
从德国首战失利到企业数据加速解决方案 数据处理与存储支持服务的未来机遇