切片集群 数据激增时,选择加内存还是加实例?
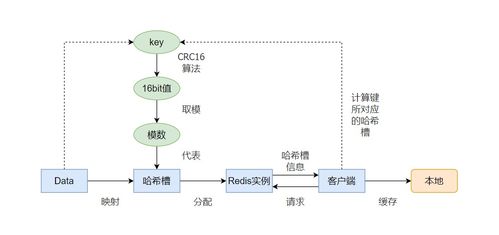
在数据处理和存储支持服务中,面对数据量的快速增长,一个常见的技术决策是:应该通过增加单个实例的内存来提升处理能力,还是通过增加更多实例来构建切片集群?这个选择不仅关系到系统的性能和成本,还直接影响着服务的可扩展性和可靠性。
理解切片集群
切片集群(Sharded Cluster)是一种将数据分散存储在多个独立实例上的架构模式。每个实例(或分片)负责处理数据集的一个子集,从而共同承担整体的数据存储和计算负载。这种架构常用于分布式数据库(如MongoDB、Redis Cluster)和大数据处理框架中,旨在突破单机资源的限制。
加内存 vs. 加实例:关键考量因素
1. 数据处理需求
- 加内存:适用于数据需要频繁进行复杂计算或缓存的场景。增加内存可以减少磁盘I/O,显著提升单次查询或事务的处理速度,尤其适合数据全集需要常驻内存的应用(如实时分析、缓存服务器)。
- 加实例:适用于数据可分区且并行处理需求高的场景。通过水平扩展,多个实例可以同时处理不同的数据切片,提高整体吞吐量,适合高并发读写、数据分片查询的业务。
2. 数据规模与增长趋势
- 如果数据量已经接近或超过单机内存上限,且预计将持续增长,那么单纯加内存可能很快再次遇到瓶颈。此时,采用切片集群加实例的方式,可以线性扩展存储容量和处理能力,更具前瞻性。
3. 可用性与可靠性
- 加内存通常意味着依赖更少、更强大的服务器,但单点故障风险较高。
- 加实例构建的切片集群天然具备冗余和故障转移能力,当某个实例失效时,集群可以继续服务(需配合副本机制),从而提升系统的整体可用性。
4. 成本与运维复杂性
- 加内存可能涉及升级现有硬件或更换为更高配的服务器,前期成本可能较高,但运维相对简单。
- 加实例通常可以利用更多标准化的、成本更低的硬件,但会引入分布式系统的复杂性,如数据分片策略、负载均衡、一致性问题等,对运维团队的要求更高。
5. 性能特征
- 加内存主要优化了单请求的延迟,因为数据访问更快。
- 加实例主要优化了系统的整体吞吐量,通过并行处理支持更多并发请求。
实践建议
- 评估工作负载:首先分析应用的数据访问模式。是读多写少还是写多读少?是否需要复杂的事务支持?这些因素将影响选择。
- 进行容量规划:基于历史增长数据预测未来的存储和计算需求。如果数据量预计会持续、快速增长,尽早规划切片集群架构往往是更可持续的选择。
- 考虑混合方案:在实际场景中,两者并非互斥。例如,可以为每个切片实例配置充足的内存,以确保每个分片内部的性能最优。即,在增加实例(水平扩展)的也为每个实例配备足够的内存资源。
- 利用云服务的弹性:在云环境中,可以更灵活地结合两者。例如,使用自动扩展组,根据负载动态调整实例数量,同时为实例类型选择合适的内存配置。
结论
在数据处理和存储服务中,面对数据增多,选择“加内存”还是“加实例”并非一刀切。加内存是垂直扩展,适用于提升单机处理能力、降低延迟的场景;而加实例构建切片集群是水平扩展,旨在突破单机限制,提高吞吐量、存储容量和可用性。 对于大多数持续增长的业务,采用切片集群(加实例)的架构更能适应未来的扩展需求,但需要投入更多精力设计分片策略和管理分布式系统。明智的做法是基于具体的业务需求、性能指标、成本预算和运维能力,做出平衡的决策,并在必要时采用混合策略,以实现最优的数据处理与存储支持。
最新产品
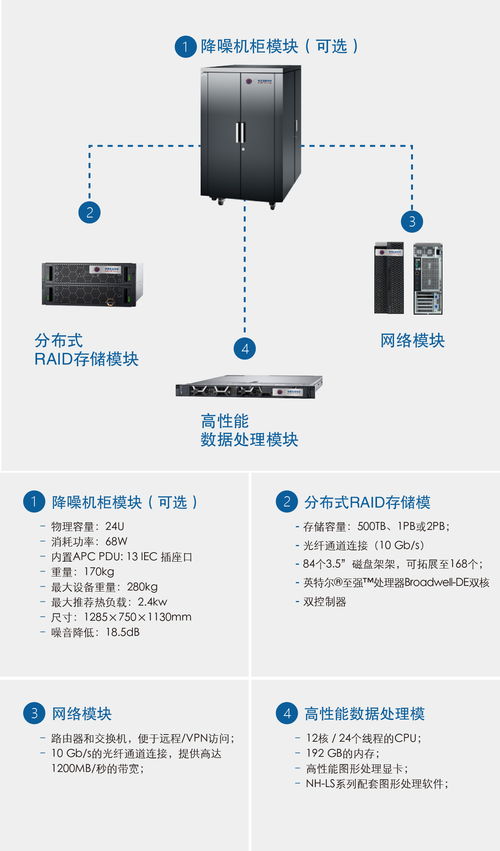
锘海nh dsap系列 数据存储与处理的完整解决方案
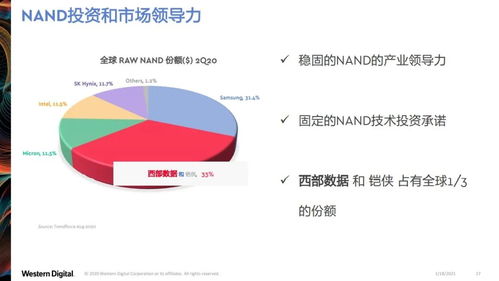
西部数据 数据驱动万物时代的存储分层之道
数字化时代的基石 数据存储表示法及其与处理和存储支持服务的关系
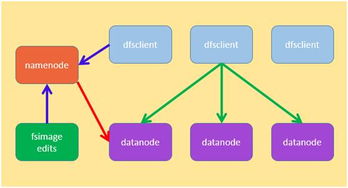
分布式数据库存储设计的革新 构建高效、可靠的数据处理与存储支持服务体系
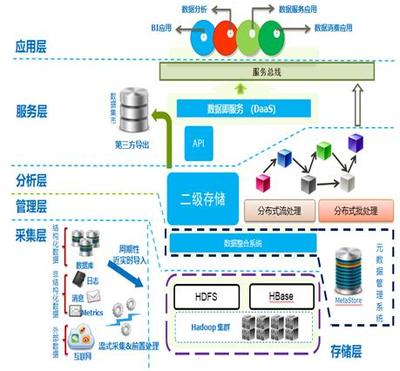
云操作系统研发与应用国家地方联合工程研究中心 数据处理与存储支持服务的技术架构与应用价值
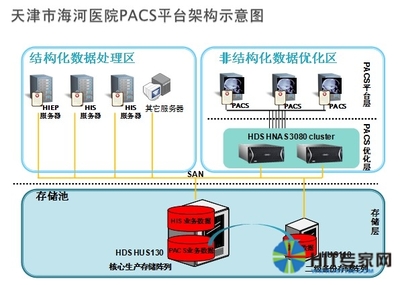
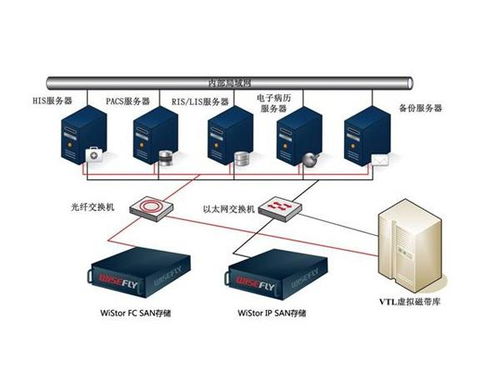
天津海河医院 突破影像调阅速度瓶颈,以数据处理与存储支持服务赋能智慧医疗
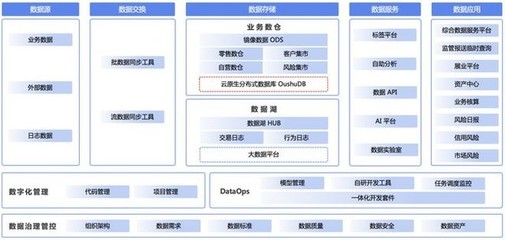
OushuDB × 东方证券 数据仓库信创国产化最佳实践与全栈服务支持
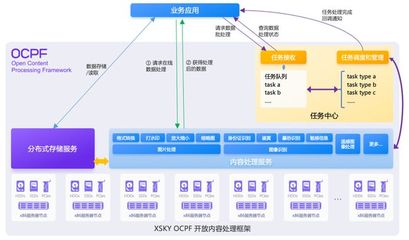
XSKY推出OCPF开放内容处理框架,首期聚焦图片处理能力,赋能数据处理与存储服务
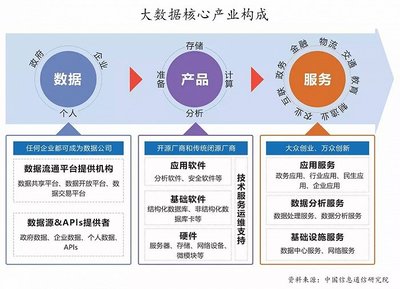
大数据 解锁大问题的钥匙与数据处理、存储的支撑服务
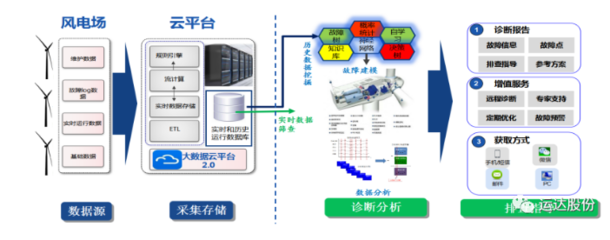
运达股份风电机组智能故障诊断系统2.0正式上线,数据服务全面升级