高可用存储架构的设计与思考 构建坚实的数据处理与存储支持服务
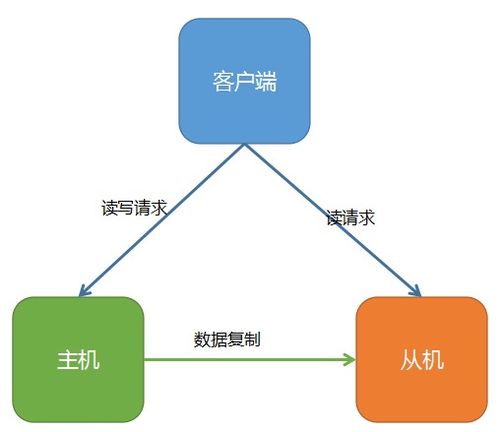
在当今数据驱动的时代,数据处理与存储服务的可靠性直接关系到业务的连续性与用户体验。高可用存储架构的设计,其核心目标是在面对硬件故障、网络波动、软件异常甚至自然灾害等挑战时,确保数据的持久性与服务的持续性。这不仅是一项技术任务,更是一种关乎业务韧性的战略思考。
一、 核心设计原则:超越简单的冗余
高可用架构的基石在于消除单点故障。这远不止部署双机热备那么简单,而是一个系统性工程。关键原则包括:
- 冗余与隔离:在数据层(多副本存储)、服务层(无状态应用多实例)和基础设施层(多可用区/地域部署)实现冗余,并确保故障域之间的有效隔离,防止级联失效。
- 自动化故障转移与恢复:系统应能自动检测故障,并快速、平滑地将流量与服务切换至健康节点,整个过程对上层应用透明,最大限度地减少人工干预和停机时间。
- 可观测性与预警:建立完善的监控指标(如I/O延迟、吞吐量、节点健康状态、错误率),通过日志、追踪和度量系统实现全景监控,并设置智能预警,在问题影响用户前提前发现。
- 弹性伸缩:架构应能根据负载动态伸缩,既能应对流量洪峰,也能在低谷时节约资源,这本身也是保障服务能力持续可用的一种方式。
二、 分层架构下的高可用实践
现代高可用存储架构通常是分层的,每一层都有其设计要点:
- 接入层与元数据层:作为请求入口和数据的“导航图”,必须采用高可用的分布式设计,如基于Raft/Paxos共识算法的集群,确保元数据的一致性与可用性。
- 数据存储层:这是设计的重中之重。对象存储、块存储、文件存储各有策略。主流做法是采用多副本机制(如三副本),并结合纠删码技术,在存储效率与可靠性间取得平衡。数据分片与跨机架、跨可用区的分布策略,能有效分散风险。
- 数据处理层:计算与存储分离已成为云原生时代的主流范式。计算资源(如Spark、Flink集群)的无状态化设计,使其可以快速拉起和销毁,依赖底层存储的高可用性来保证数据可靠性。批流一体的处理框架也需要考虑状态后端(如RocksDB)的高可用部署。
三、 关键技术选型与权衡
设计过程中充满权衡:
- 一致性、可用性与分区容忍性(CAP):根据业务场景选择。对于核心交易数据,可能选择CP模型(如etcd);对于海量非结构化数据,可能偏向AP模型(如Cassandra)。最终一致性配合冲突解决机制是分布式存储的常见选择。
- 存储引擎:LSM-Tree与B-Tree各有优劣,选择需考虑读写模式、延迟要求及压缩效率。
- 网络与延迟:跨地域多活架构能提供最高级别的容灾能力,但会引入数据同步延迟和一致性问题,需要精细的数据同步策略(如同步/异步复制)和冲突处理机制。
四、 面向未来的思考:云原生与智能化
高可用架构的设计正在演进:
- 云原生融合:容器化部署、Kubernetes编排以及服务网格(Service Mesh)的引入,使得存储服务的部署、调度和治理更加标准化和自动化,极大地提升了弹性与可管理性。
- 数据生命周期智能管理:结合AIops,根据数据的热度自动在不同存储介质(高速SSD、标准硬盘、归档存储)间流动,在保证性能的同时优化成本。智能预测故障盘、提前进行数据迁移,变被动响应为主动防御。
- 安全与高可用一体化:加密(静态/传输中)、细粒度访问控制和不可变存储等安全特性,已成为高可用架构不可或缺的部分,确保数据既“拿得到”,也“丢不了”、“看不了”。
结论
设计高可用的数据处理与存储支持服务,是一个融合了分布式系统理论、硬件知识、业务理解和运维实践的持续过程。没有一劳永逸的“银弹”,关键在于深刻理解自身业务的数据模式、一致性要求与容灾目标,构建一个具备韧性、可观测、可自动化运维的体系。它最终保障的,不仅是数据的比特位,更是业务的命脉与用户的信任。
最新产品
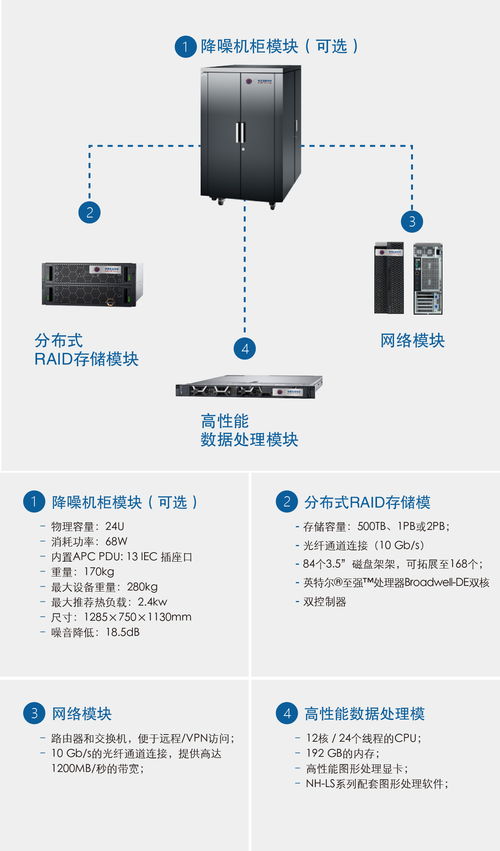
锘海nh dsap系列 数据存储与处理的完整解决方案
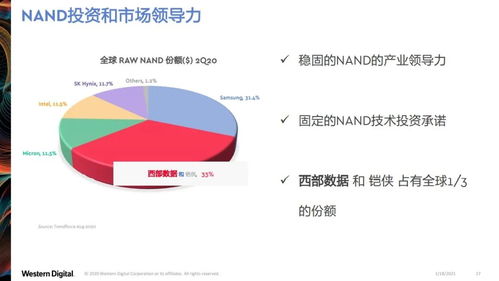
西部数据 数据驱动万物时代的存储分层之道
数字化时代的基石 数据存储表示法及其与处理和存储支持服务的关系
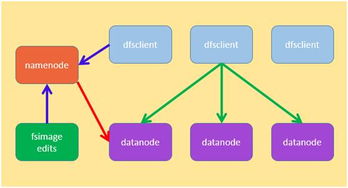
分布式数据库存储设计的革新 构建高效、可靠的数据处理与存储支持服务体系
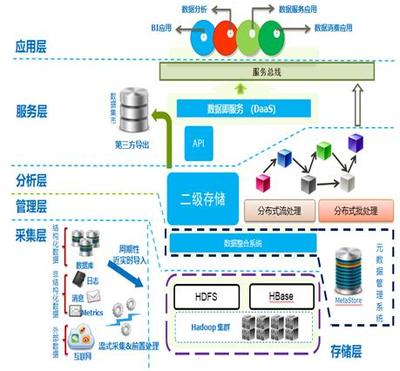
云操作系统研发与应用国家地方联合工程研究中心 数据处理与存储支持服务的技术架构与应用价值
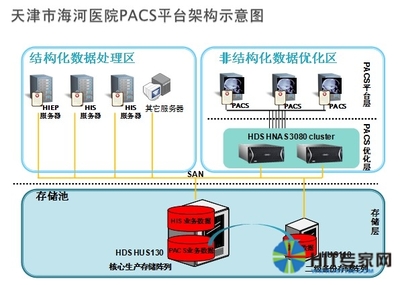
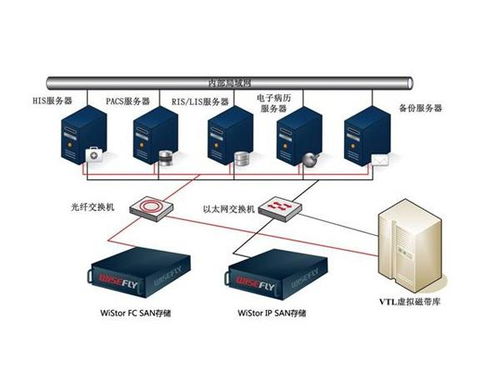
天津海河医院 突破影像调阅速度瓶颈,以数据处理与存储支持服务赋能智慧医疗
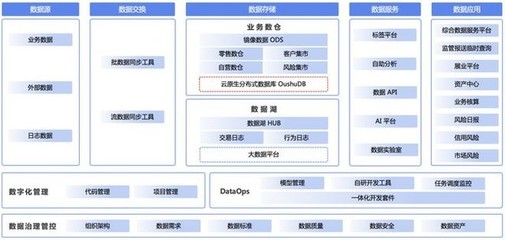
OushuDB × 东方证券 数据仓库信创国产化最佳实践与全栈服务支持
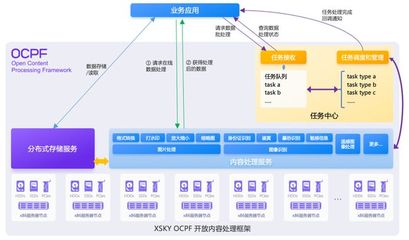
XSKY推出OCPF开放内容处理框架,首期聚焦图片处理能力,赋能数据处理与存储服务
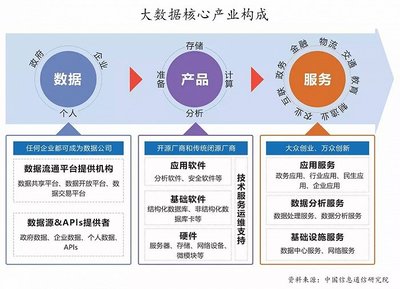
大数据 解锁大问题的钥匙与数据处理、存储的支撑服务
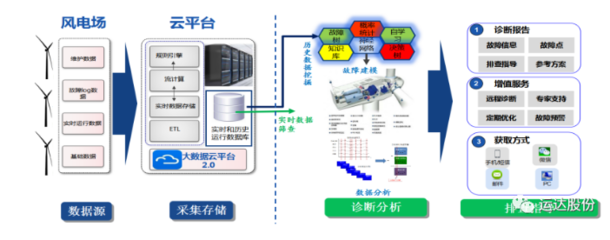
运达股份风电机组智能故障诊断系统2.0正式上线,数据服务全面升级