存储管理的演进 数据库优化与大数据处理存储支持服务
在数字化浪潮席卷全球的今天,数据已成为驱动企业发展的核心生产要素。从传统的结构化数据到如今的非结构化海量数据流,如何高效、可靠、经济地管理、处理与存储数据,已成为技术领域的关键课题。本文将围绕存储管理、数据库优化以及大数据处理与存储支持服务三个层面,探讨其内在联系与协同演进。
一、 存储管理:数据存取的基石
存储管理是数据处理体系的底层基础,其核心目标是确保数据的安全性、可用性和高性能存取。传统存储架构,如直接附加存储(DAS)、网络附加存储(NAS)和存储区域网络(SAN),主要服务于结构化数据和关键业务应用。随着数据量的爆炸式增长和数据类型的多样化,现代存储管理正朝着软件定义存储(SDS)、超融合基础设施(HCI)和云存储方向发展。这些技术通过抽象化硬件资源,实现了更高的灵活性、可扩展性和成本效益,为上层的数据处理应用提供了坚实、弹性的支撑平台。
二、 数据库优化:提升核心业务效能
数据库作为存储和管理结构化数据的核心系统,其性能直接关系到业务应用的响应速度和用户体验。数据库优化是一个系统工程,涵盖多个层面:
1. 架构设计优化:合理的表结构设计、索引策略(如B树、位图索引)以及范式与反范式的权衡,能从根源上提升查询效率。
2. 查询优化:通过分析执行计划、重写低效SQL语句、利用查询提示或优化器引导,减少不必要的全表扫描和连接操作。
3. 资源配置优化:根据工作负载特性,调整内存分配(如缓冲池、排序区)、I/O配置以及并发连接数,确保数据库引擎高效运行。
4. 高可用与扩展优化:采用主从复制、分库分表、读写分离乃至新型的分布式数据库架构,以应对高并发访问和海量数据存储挑战。
优化的本质是在有限的存储与计算资源下,让数据库系统以最高的效率服务于业务逻辑。
三、 大数据处理与存储支持服务:应对规模化挑战
当数据规模、速度和多样性超出传统数据库的舒适区时,便进入了大数据领域。大数据处理涉及批处理(如Hadoop MapReduce)、实时流处理(如Apache Flink, Apache Storm)和交互式查询(如Apache Hive, Presto)等多种模式。这背后离不开新一代存储支持服务的支撑:
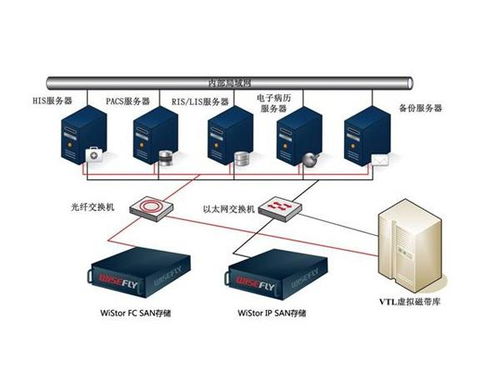
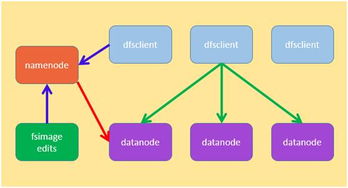
- 分布式文件系统:如HDFS、Ceph,它们将海量数据分散存储在低成本服务器集群上,提供高吞吐量的数据访问能力,是大数据生态的存储基石。
- NoSQL与NewSQL数据库:如MongoDB(文档型)、Cassandra(列族型)、Redis(键值型)以及TiDB(分布式关系型),它们针对特定的大数据场景(高并发、半结构化、水平扩展)提供了优化的数据模型和存储引擎。
- 数据湖与对象存储:如基于AWS S3、阿里云OSS构建的数据湖,允许以原始格式存储海量异构数据(文本、图像、日志等),为后续的探索性分析和机器学习提供了灵活的数据底座。
- 一体化数据平台服务:云厂商提供的如数据仓库(Snowflake, BigQuery)、数据湖分析、流数据摄取等托管服务,集成了存储、计算、管理和分析工具,极大降低了企业构建和维护大数据平台的技术门槛与成本。
四、 融合与协同:构建一体化数据战略
存储管理、数据库优化与大数据服务并非孤立存在,而是紧密关联、层层递进。现代数据架构往往采用混合或多层设计:
- 将在线事务处理(OLTP)的核心业务数据存放在经过深度优化的关系型数据库中,确保ACID属性和低延迟。
- 将历史数据、日志、点击流等大数据量、低价值密度数据迁移至数据湖或低成本对象存储中。
- 利用大数据处理框架(如Spark)对湖仓中的数据进行分析、清洗和转换,结果可反馈至优化后的数据库供业务系统使用,或存入专门的分析型数据库(OLAP)支持决策。
- 统一的存储管理策略和生命周期策略,实现数据在热、温、冷存储介质间的自动流动,优化总体拥有成本(TCO)。
###
从精细化的单机数据库优化,到面向海量异构数据的大规模分布式处理与存储,技术演进的主线始终是围绕数据的价值实现。未来的趋势将是智能化存储管理、自治数据库与云原生大数据服务的深度融合。企业需要根据自身的业务特点、数据规模和成本预算,制定弹性的、可持续演进的数据架构,让存储、处理与优化三者协同,共同支撑起数据驱动业务创新的宏伟蓝图。
最新产品