TFRecords 高效数据处理与存储的关键支持服务
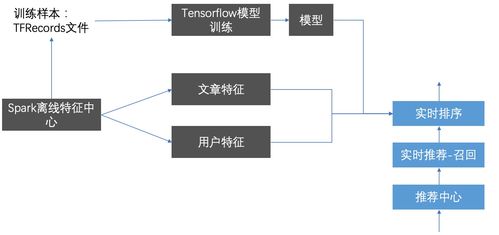
在机器学习与深度学习项目的生命周期中,数据处理的效率和质量往往是决定模型成败的关键因素之一。面对海量、多源、结构各异的训练数据,如何高效地进行组织、存储、读取和传输,是工程师们必须解决的核心问题。TensorFlow 框架提供的 TFRecords 格式,正是为解决这一系列挑战而设计的强大数据处理与存储支持服务。
一、 TFRecords 的核心价值:专为 TensorFlow 优化的存储格式
TFRecords 是 TensorFlow 官方推荐的一种二进制文件格式,它将数据序列化为 tf.train.Example Protocol Buffer 消息进行存储。其核心设计目标在于与 TensorFlow 的数据读取管道(tf.data API)实现无缝、高效集成。相比直接读取原始图像、CSV 或 JSON 文件,TFRecords 格式具有显著优势:
- 高效的存储与读取:二进制格式体积更小,I/O 效率更高,特别适合在分布式训练环境中进行快速的数据加载,有效避免了小文件读写带来的性能瓶颈。
- 序列化存储:能够将图像数据、标签、文本、数值特征等异构数据统一封装在一条记录中,简化了数据管理逻辑。
- 与
tf.data管道深度集成:TFRecords 文件可以方便地使用tf.data.TFRecordDataset进行读取,并配合map、shuffle、batch、prefetch等操作,构建出高效、灵活的数据输入流水线,使得 CPU 的数据预处理与 GPU 的模型计算能够充分并行。
二、 数据处理流程:从原始数据到 TFRecords
构建 TFRecords 文件是一个标准化的数据处理流程,主要包含以下步骤:
- 数据准备与解析:从原始来源(如数据库、文件系统、网络)收集数据,并进行必要的清洗、归一化或标注。
- 特征字典构建:将每个样本(如图像及其标签)的所有信息,按照 TensorFlow 支持的数据类型(
BytesList,FloatList,Int64List)构建为一个特征字典。 - 序列化为 Example:使用
tf.train.Example将特征字典序列化。 - 写入 TFRecords 文件:将序列化后的
Example对象写入一个或多个 TFRecords 文件。通常建议将大数据集切分为多个文件(Sharding),以便于并行读取和分布式处理。
这个流程本身可以作为一项重要的数据支持服务,通过自动化脚本或数据流水线工具,将杂乱的数据源转化为模型训练可直接消费的高质量、标准化“燃料”。
三、 存储支持服务:TFRecords 在工程实践中的角色
在大型项目或企业级机器学习平台中,围绕 TFRecords 可以构建一套完整的数据存储支持服务体系:
- 标准化与版本管理:TFRecords 文件格式统一,便于对训练数据集进行版本控制,追踪不同版本数据与模型性能的对应关系。
- 高效缓存与分发:二进制文件适合作为构建数据缓存层的基础格式。在云端训练场景中,可以先将预处理好的 TFRecords 文件存储在对象存储(如 AWS S3, Google Cloud Storage)中,训练时再快速流式读取到计算实例,减少重复预处理开销。
- 数据管道即服务:将生成 TFRecords 的流程封装为可配置的、可调度的服务。数据工程师只需提交数据源和配置(如图像尺寸、编码方式),该服务即可自动完成从原始数据到标准化 TFRecords 的转换,供算法团队随时取用。
- 性能优化关键:通过调整 TFRecords 文件的大小、数量,以及配合
tf.dataAPI 的并行读取、预取等策略,可以最大化 I/O 吞吐量,确保昂贵的 GPU 计算资源不会因数据供给不足而闲置。
四、 与展望
TFRecords 远不止是一种文件格式,它是连接原始数据与 TensorFlow 计算图的高性能桥梁,是构建工业化机器学习流水线不可或缺的一环。它将数据处理中的存储、序列化、读取等复杂细节封装起来,让算法开发者能更专注于模型本身。
尽管 PyTorch 等框架有其各自的数据加载方式(如 Dataset 和 DataLoader),但 TFRecords 所体现的设计思想——即通过标准化、序列化的存储格式来优化 I/O 性能,并与框架原生数据工具深度集成——具有普遍的借鉴意义。随着机器学习项目规模不断扩大,将数据处理与存储作为一项核心支持服务来系统化地建设和优化,已成为提升团队整体效率和模型迭代速度的必然选择。
最新产品