数据处理与存储的基石 深度解析B树的原理与应用
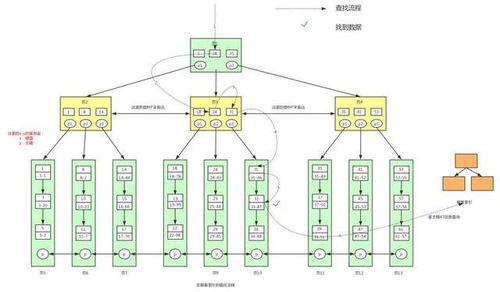
B树(B-Tree)作为计算机科学中一种重要的数据结构,自1970年由Rudolf Bayer和Edward M. McCreight提出以来,便成为大规模数据处理和存储系统不可或缺的基石。其设计初衷是为了解决磁盘等外存设备上高效存储与检索大量数据的问题。理解B树,意味着掌握了现代数据库系统和文件系统高效运作的核心逻辑之一。
B树的核心设计思想
B树是一种平衡的多路搜索树,与常见的二叉树(如二叉搜索树、AVL树)不同,B树的每个节点可以拥有多个子节点(通常远多于两个)。这一特性是其高效性的关键。其主要设计目标是最小化磁盘I/O次数。由于磁盘访问速度远慢于内存,减少从磁盘读取数据的次数能极大提升性能。
B树的定义基于一个关键参数:阶数(order,通常记为m)。一棵m阶B树满足以下性质:
- 多路平衡:每个节点最多有m个子节点(除根节点外)。
- 关键码有序:每个节点内的关键码(key)按升序排列。
- 子节点分割:非叶节点如果有k个关键码,则恰好有k+1个子节点。
- 叶节点等高:所有叶节点都位于同一层,这保证了树的绝对平衡。
- 关键码数量限制:除根节点外,每个节点至少有⌈m/2⌉-1个关键码(即最少有⌈m/2⌉个子节点)。根节点至少有一个关键码(除非树为空)。
B树如何支撑数据处理与存储服务
1. 高效检索
B树的查找过程从根节点开始,在节点内部进行(内存中的)二分查找,确定下一个需要访问的子节点指针,然后递归进行。由于节点容量大(一个节点的大小通常设计为与磁盘页/块大小匹配,如4KB),树的高度非常低。例如,一个存储10亿条记录的B树,高度可能仅为3-4层。这意味着查找任意记录最多只需3-4次磁盘I/O,效率极高。
2. 顺序访问与范围查询
B树的所有关键码在叶节点层按顺序链接(通常通过指针),形成了一个有序链表。这使得范围查询(如“查找年龄在20到30岁之间的所有记录”)异常高效:先定位到范围下界的叶节点,然后沿链表顺序读取即可,避免了回溯父节点。
3. 插入与删除的自我平衡
B树通过精妙的节点分裂与合并操作来维持平衡,确保上述优越性能在动态数据更新中得以保持。
- 插入:当向一个已满的节点插入新关键码时,该节点会分裂成两个节点,并将中间关键码提升到父节点。这个过程可能递归向上,但树的高度增长非常缓慢。
- 删除:删除关键码可能导致节点关键码数低于下限。此时,B树会尝试从兄弟节点“借”一个关键码,或者与兄弟节点合并,同样可能递归向上调整。这些操作都保证了树始终保持平衡和低矮。
4. 在现代系统中的应用
- 关系型数据库索引:如MySQL的InnoDB存储引擎、Oracle、PostgreSQL等,其核心的索引结构就是B+树(B树的一种变体,所有数据都存储在叶节点,非叶节点仅存关键码和指针,使查询更稳定,范围查询能力更强)。
- 文件系统:许多文件系统(如NTFS、ReiserFS、XFS)使用B树或B+树来管理元数据(如目录结构、文件分配信息),以实现快速的目录查找和文件管理。
- 非关系型数据库与存储引擎:即使在一些NoSQL数据库(如MongoDB的WiredTiger存储引擎)和分布式存储系统中,B树或其变体也常作为底层存储索引结构。
###
B树的卓越之处在于它完美地弥合了高速CPU与低速磁盘之间的速度鸿沟。其“矮胖”的树形结构、节点大小与磁盘块的匹配、高效的平衡维护算法,共同构成了一个能够支撑海量数据持久化存储与快速检索的坚实框架。可以说,正是B树及其变体,为当今从企业级数据库到个人电脑文件系统等广泛的数据处理和存储支持服务,提供了最核心、最可靠的高效访问能力。理解了B树,就理解了现代数据系统高效性的一个底层密码。
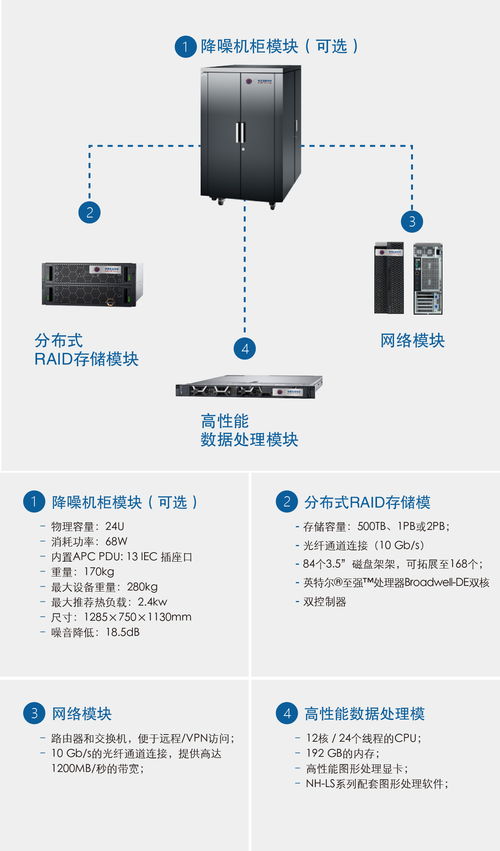
最新产品